See inside your AI pipeline. AgentLens lets you watch your agents reason, grade, and judge – every LLM call, from thinking to response.
Upload your documents. Ask anything. Get precise answers – powered by a team of AI agents working across your knowledge base.
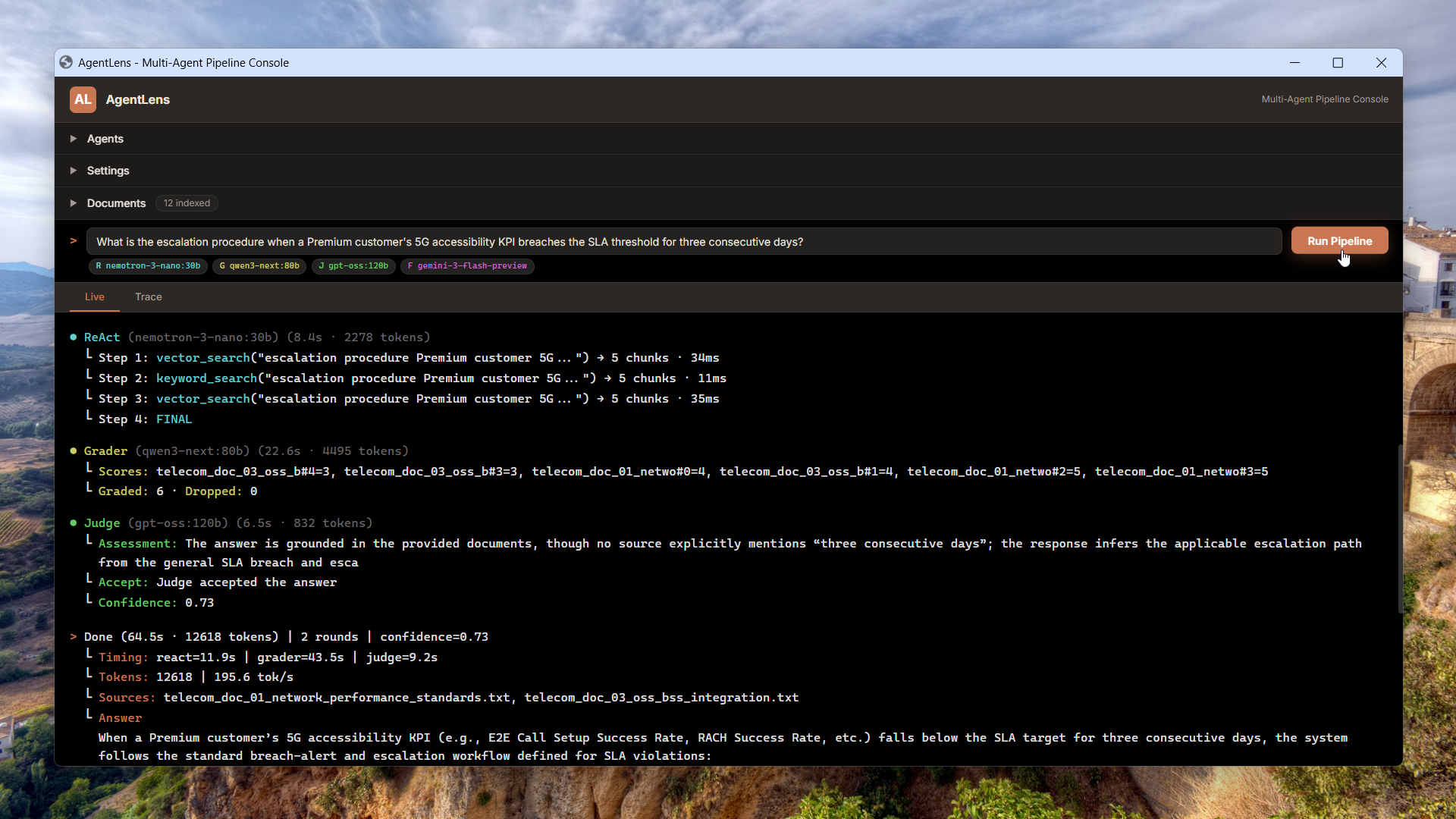
ReAct loop with hybrid vector + BM25 retrieval
An autonomous agent reasons step-by-step through a ReAct loop – choosing between semantic vector search and BM25 keyword search on each iteration, merging and deduplicating chunks until it has enough evidence to answer.
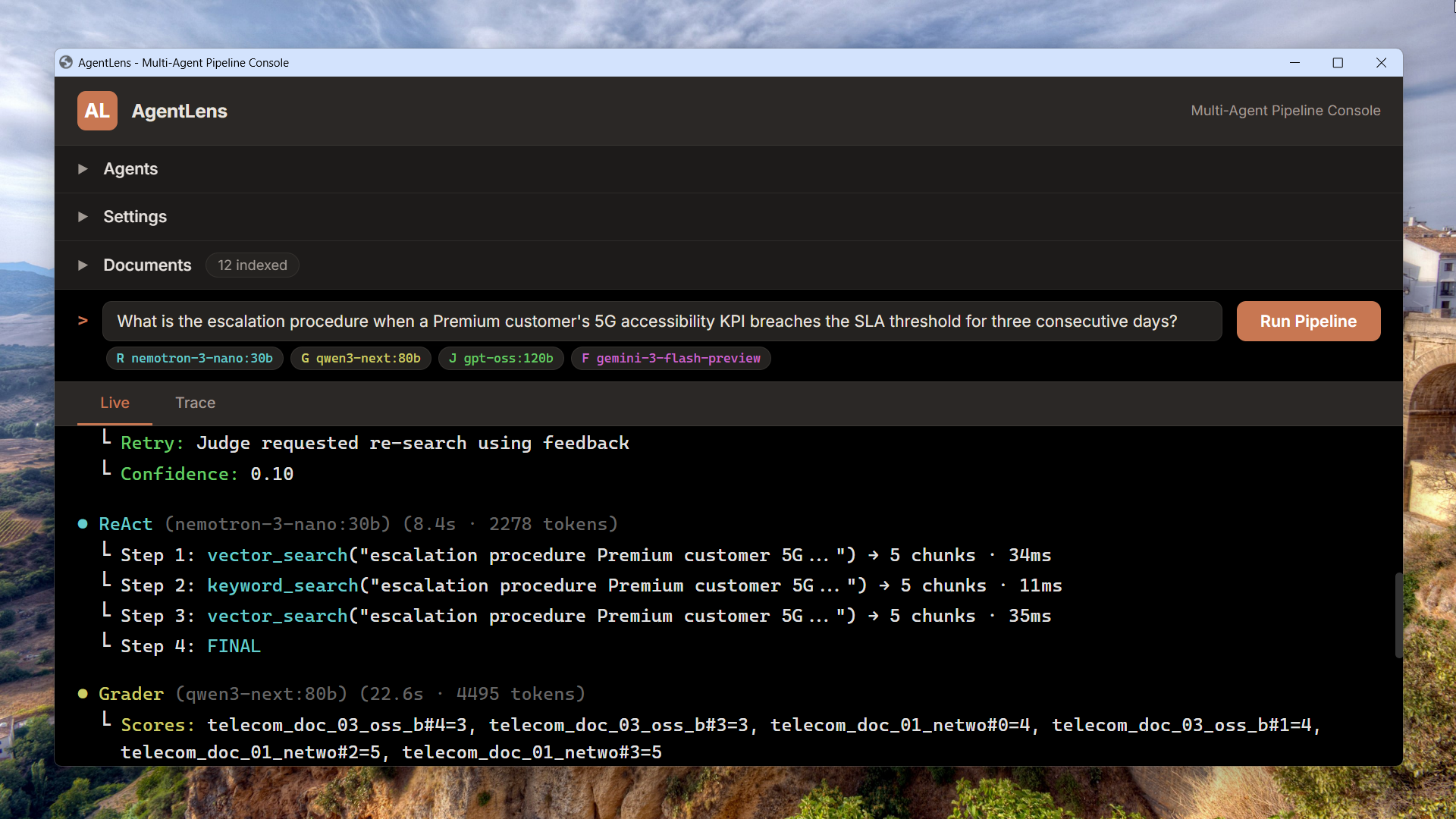
CRAG-style grading with a quality judge
A retrieval grader scores every chunk on a 1-5 relevance scale, filtering noise before a second LLM – the Quality Judge – evaluates the answer for groundedness and completeness. If the verdict is RETRY, targeted feedback steers the next retrieval round.
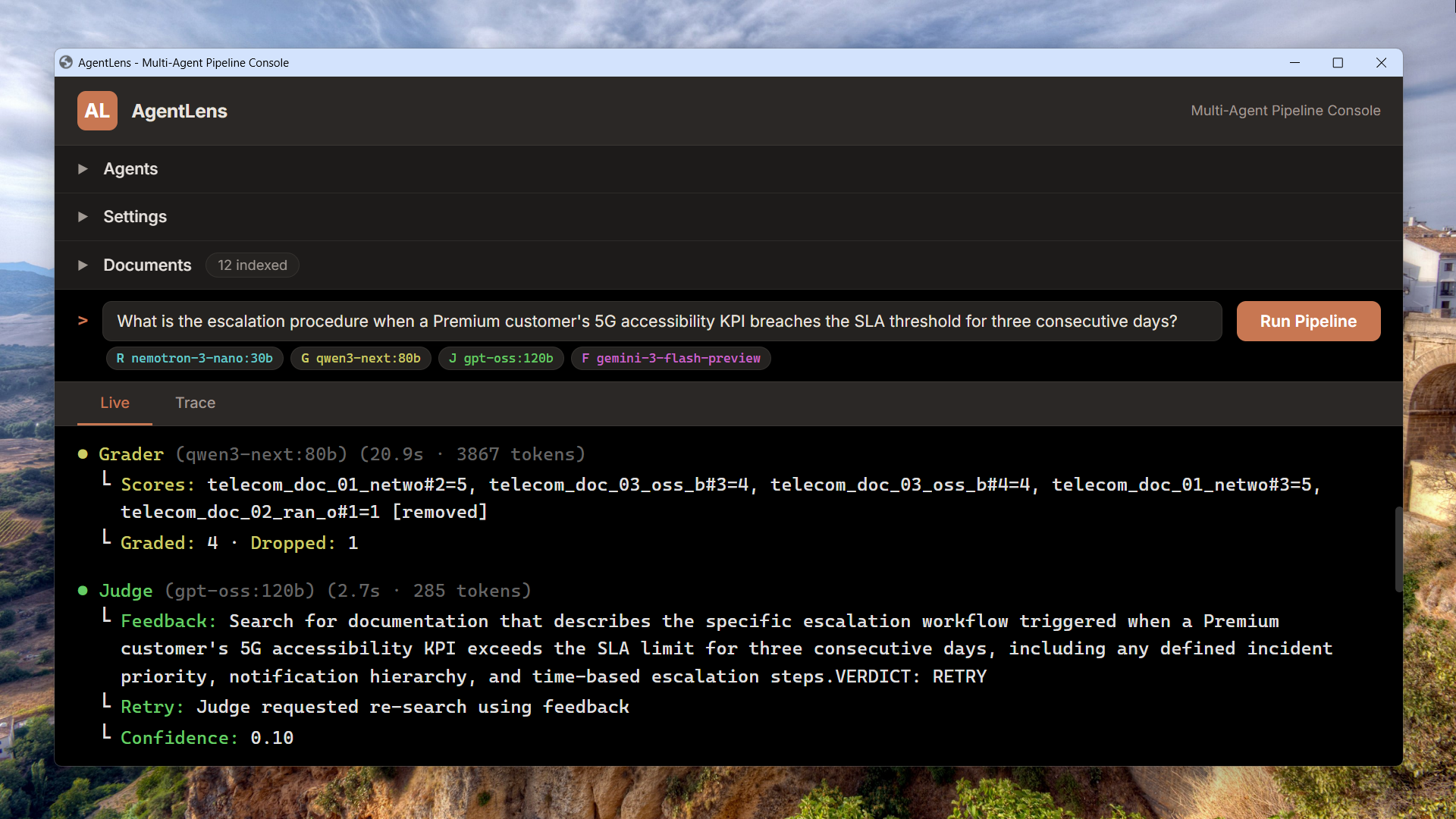
Prompt, Thinking, and Raw Response on every call
Open any pipeline stage in the Trace view and inspect three layers: the exact prompt sent to the LLM, the chain-of-thought reasoning (when thinking is enabled), and the raw text returned. Live tab streams execution in real time; Trace tab lets you replay it call by call.
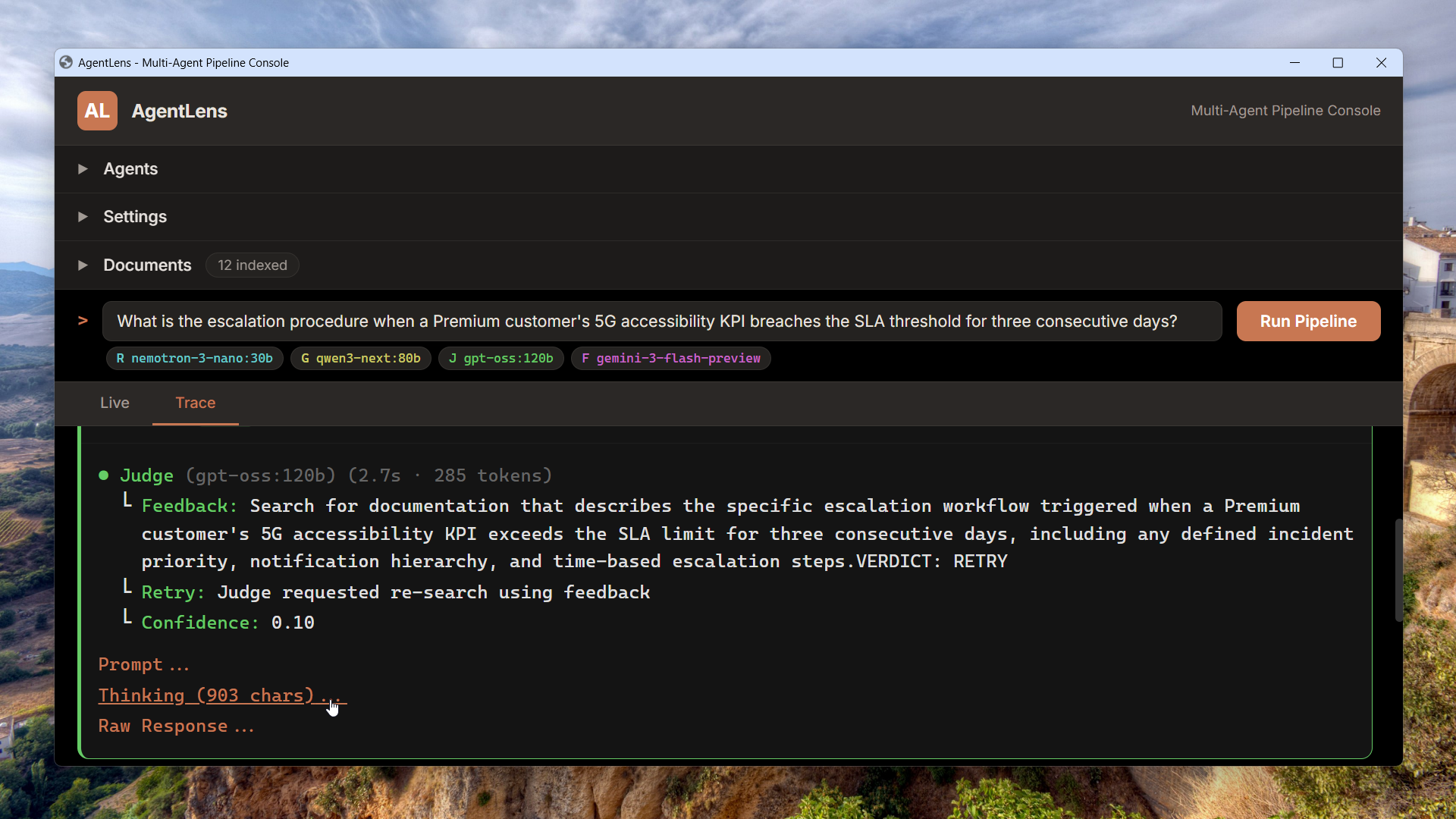
Choose any model
Pick the right model for the job
Each pipeline role – ReAct agent, Grader, Judge, Fallback – gets its own model picker. Mix fast models for retrieval with stronger ones for evaluation, and swap them without restarting.
Models overview →Thinking models built in
Toggle chain-of-thought reasoning per role. See the model think through retrieval decisions, grading logic, and quality evaluation – all visible in the Trace view.
Thinking Layer →From 3B to 1T parameters
Lightweight 3B‑4B models for fast iteration, mid-range defaults like nemotron‑3‑nano:30b, qwen3‑next:80b, and gpt‑oss:120b for production, and frontier models up to glm‑5 and kimi‑k2.5 at 1T parameters. 30+ models from Ollama Cloud, all through the same pipeline.
Browse library →Built by Adityo Nugroho
Designed and built end-to-end retrieval-augmented generation systems – from microservice architecture and infrastructure-as-code to multi-agent orchestration with autonomous reasoning, quality evaluation, and retry feedback loops. A 4-service pipeline with ReAct agents, CRAG-style grading, hybrid retrieval (vector + BM25), token-budgeted prompt assembly, and real-time streaming observability. Deployed to production on AWS with Terraform, Docker, and Nginx reverse proxy. No frameworks, no LangChain, no LlamaIndex – 260+ tests.